Scrape Amazon Reviews using Python
Web scraping is one of the best ways to automate collecting a large set of data according to our needs. The program that is used to scrape a website is called a web crawler.
The origin of scraping goes back to the time where the internet was a collection of File Transfer Protocol (FTP) sites. It was daunting to search for information or data on these sites. Users had to navigate the sites to find specific shared files. As a solution to this problem, automated programs called web crawlers or bots were created.
However, scraping technology has improved a lot since then. There are many web crawlers built with different functionalities targeting specific tasks. While some of them are simple programs, others are very complicated.
In this article, I will show you how to scrape review data from Amazon using Scrapy. Scrapy is a free and open-source framework written in Python specifically targeting scraping.
Installation and Setup
Make sure that you have installed python as it is required to install Scrapy. There are two ways of installing Scrapy:
- We can install Scrapy using pip which is a package management tool for python.
$ pip install Scrapy
- In case you are using Anaconda, you can install it using conda.
conda install -c conda-forge Scrapy
Create a Project for Scraping
First, create a folder in which you are going to create your application. Inside this folder, we’ll run the below command to create a project using Scrapy.
scrapy startproject Scrape_AmazonReviews
Once you create the project, open the folder as a work space in your favorite editor. You will have a folder structure, as described below.
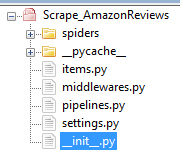
The folder structure of the crawling project
Next, we’ll create a Spider which is the real program that does the scraping. It crawls through a given URL and parses the data that are described using XPath.
In this example, we’ll create the Spider to extract data from the Amazon web page into an excel sheet in a particular format.
To create a Spider, we need to provide the URL to be crawled.
scrapy genspider spiderName your-amazon-link-her
So, as we are extracting the reviews for a particular product called "World Tech Toys Elite Mini Orion Spy Drone". The URL for this product is “https://www.amazon.com/product-reviews/B01IO1VPYG/ref=cm_cr_arp_d_viewopt_sr?pageNumber=”.
scrapy genspider AmazonReviews https://www.amazon.com/product-reviews/B01IO1VPYG/ref=cm_cr_arp_d_viewopt_sr?pageNumber=
After we create the Spider, we will take a look at folder structure and supporting files.
├── scrapy.cfg # deploy configuration file
└── Scrape_AmazonReviews # project's Python module, we just created
├── __init__.py
├── items.py # project items definition file
├── middlewares.py # project middlewares file
├── pipelines.py # project pipeline file
├── settings.py # project settings file
└── spiders # a directory where spiders are located
├── __init__.py
└── example.py # spider we just created
Once that’s done, we need to identify the patterns to be extracted from the web page before coding the Spider
Identifying the patterns from web Page
We’ll identify the XML patterns for the review page and inspect the title, ratings, comments, and reviews from this page.
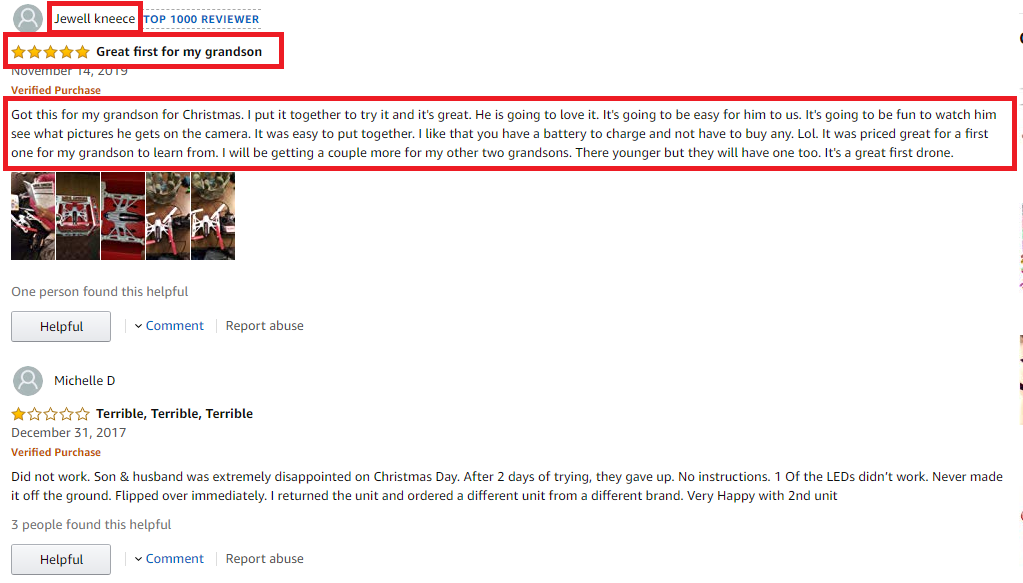
Identifying the items and patterns to be scraped
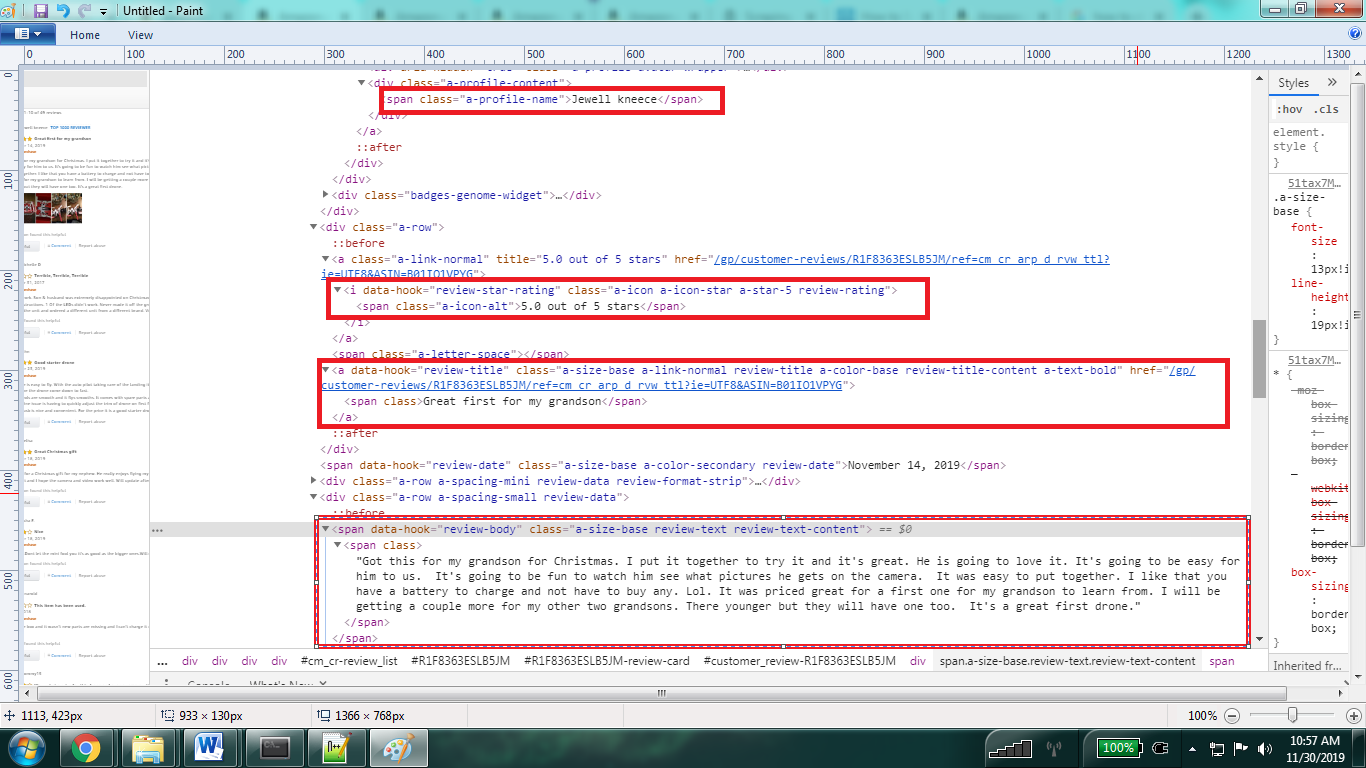
Inspecting the elements and their class
Skeleton of Spider
Once you create a Spider using a URL you will have a basic skeleton of the Spider created in the folder path “Scrape_AmazonReviews\Scrape_AmazonReviews\spiders”.
# -*- coding: utf-8 -*-
import scrapy
class AmazonReviewsSpider(scrapy.Spider):
name = "amazon_reviews"
allowed_domains = ["https://www.amazon.com/product-reviews/B01IO1VPYG/ref=cm_cr_arp_d_viewpnt_lft?pageNumber="]
start_urls = (
'https://www.amazon.com/product-reviews/B01IO1VPYG/ref=cm_cr_arp_d_viewpnt_lft?pageNumber=/',
)
def parse(self, response):
pass
Now, we’ll start extracting the data using the classes used to display the details of the reviews. Also, we will make sure that we scroll through the pages to extract the reviews.
First, we’ll set the base_url and add the number of pages to be crawled. Next, let’s extract the data using the class as identifies.
Below is the code to extract the highlighted data.
# -*- coding: utf-8 -*-
# Importing Scrapy Library
import scrapy
# Creating a new class to implement Spide
class AmazonReviewsSpider(scrapy.Spider):
# Spider name
name = 'amazon_reviews'
# Domain names to scrape
allowed_domains = ['amazon.in']
# Base URL for the World Tech Toys Elite Mini Orion Spy Drone
myBaseUrl = "https://www.amazon.com/product-reviews/B01IO1VPYG/ref=cm_cr_arp_d_viewopt_sr?pageNumber="
start_urls=[]
# Creating list of urls to be scraped by appending page number a the end of base url
for i in range(1,5):
start_urls.append(myBaseUrl+str(i))
# Defining a Scrapy parser
def parse(self, response):
#Get the Review List
data = response.css('#cm_cr-review_list')
#Get the Name
name = data.css('.a-profile-name')
#Get the Review Title
title = data.css('.review-title')
# Get the Ratings
star_rating = data.css('.review-rating')
# Get the users Comments
comments = data.css('.review-text')
count = 0
# combining the results
for review in star_rating:
yield{'Name':''.join(name[count].xpath(".//text()").extract()),
'Title':''.join(title[count].xpath(".//text()").extract()),
'Rating': ''.join(review.xpath('.//text()').extract()),
'Comment': ''.join(comments[count].xpath(".//text()").extract())
}
count=count+1
Extracting the data into the file
Once you build the Spider successfully, we can save the extracted output using runspider command. It takes the output of the Spider and stores it into a file. The runspider provides the output in formats like CSV, XML, and JSON.
To use a specific format you can use ‘-t’ to set your output format, like below.
scrapy runspider spiders/filename.py -t txt -o - > amazonreviews.txt
Here we’ll extract the output into the `.csv` file. Open the Anaconda prompt and run the below command from the folder Scrape_AmazonReviews\Scrape_AmazonReviews.
scrapy runspider spiders/AmazonReview.py -o output.csv
You will get the output in the folder Scrape_AmazonReviews\Scrape_AmazonReviews.

Amazon Reviews for World Tech Toys Elite Mini Orion Spy Drone
Summary
That being said, Scrapy is the best tool to extract the selected data and store it in the required format. By using Scrapy, we can customize the extracted data. Also, Scrapy uses a “Twisted asynchronous networking” framework to connect the given URL. Therefore, it creates a Get request and extracts the XML nodes from the given URL. The extracted data is transferred to the given output data format. Therefore, using Scrapy will never be a disappointment.